Installation
Intruction
Install on Linux
Install on Kubernetes
Related Tools
Cluster Operation
Quick Start
Cluster Admin Guide
Multi-tenant Management
Platform Management
Infrastructure
Monitoring Center
User Guide
Storage
Configuration Center
Project Settings
Development Guide
API Documentation
Nodes
A node is a worker machine in Kubernetes, a node may be a VM or physical machine, depending on the cluster. Each node contains the services necessary to run pods and is managed by the master components. Node management in KubeSphere fully meets the enterprise's requirements for cluster operation and maintenance. It supports real-time monitoring of CPU, memory, storage, Pod usage and node status, as well as the running status of the Pod on any node. In addition, it also provides rich monitoring metrics, such as CPU and memory utilization, CPU load average, IOPS, disk throughput and utilization, network badwidth, etc.
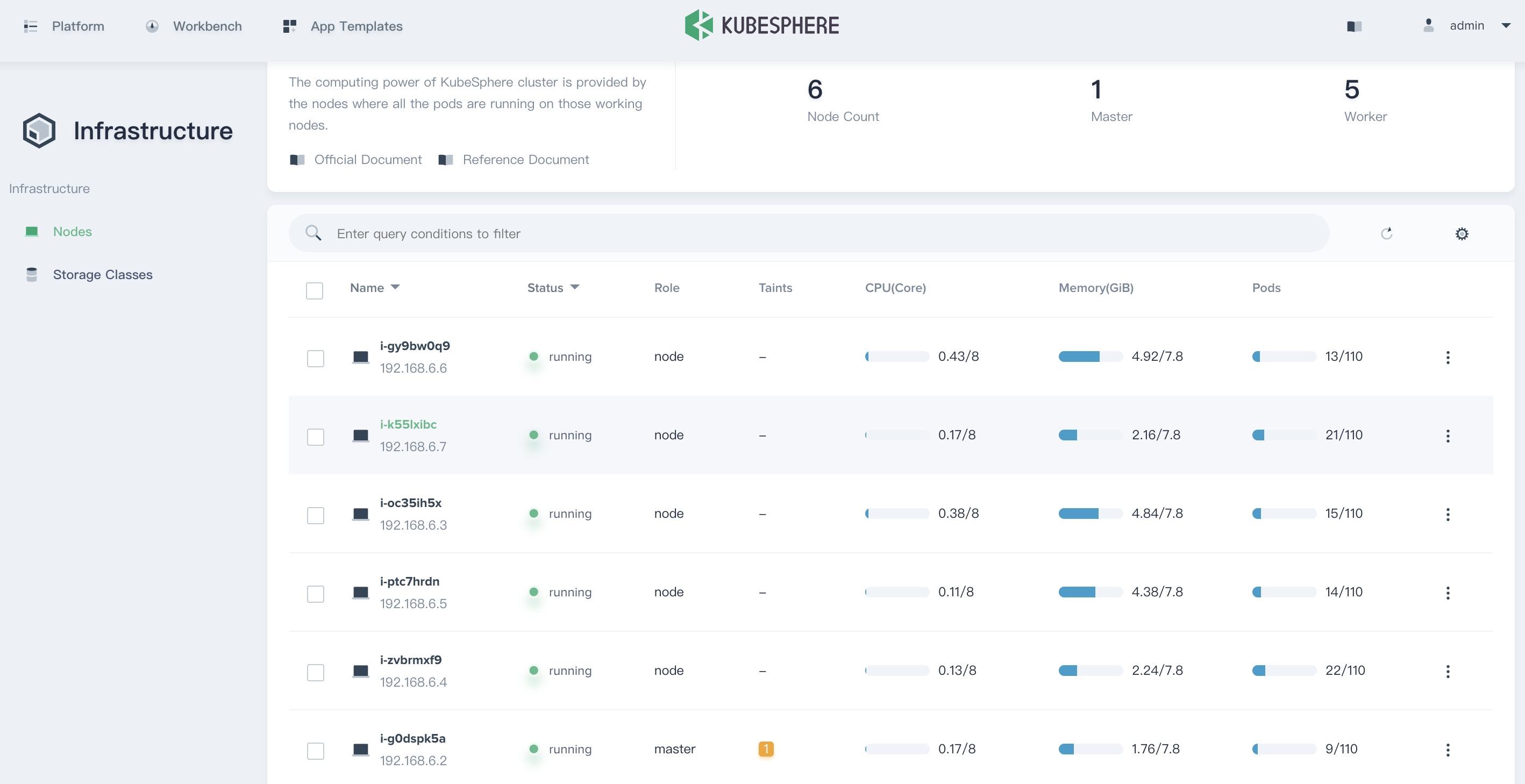
Node Management
Firstly, sign in with cluster admin, select Platform → Infrastructure, enter into the node management panel. As a cluster-admin, you can view all of nodes and monitoring details.
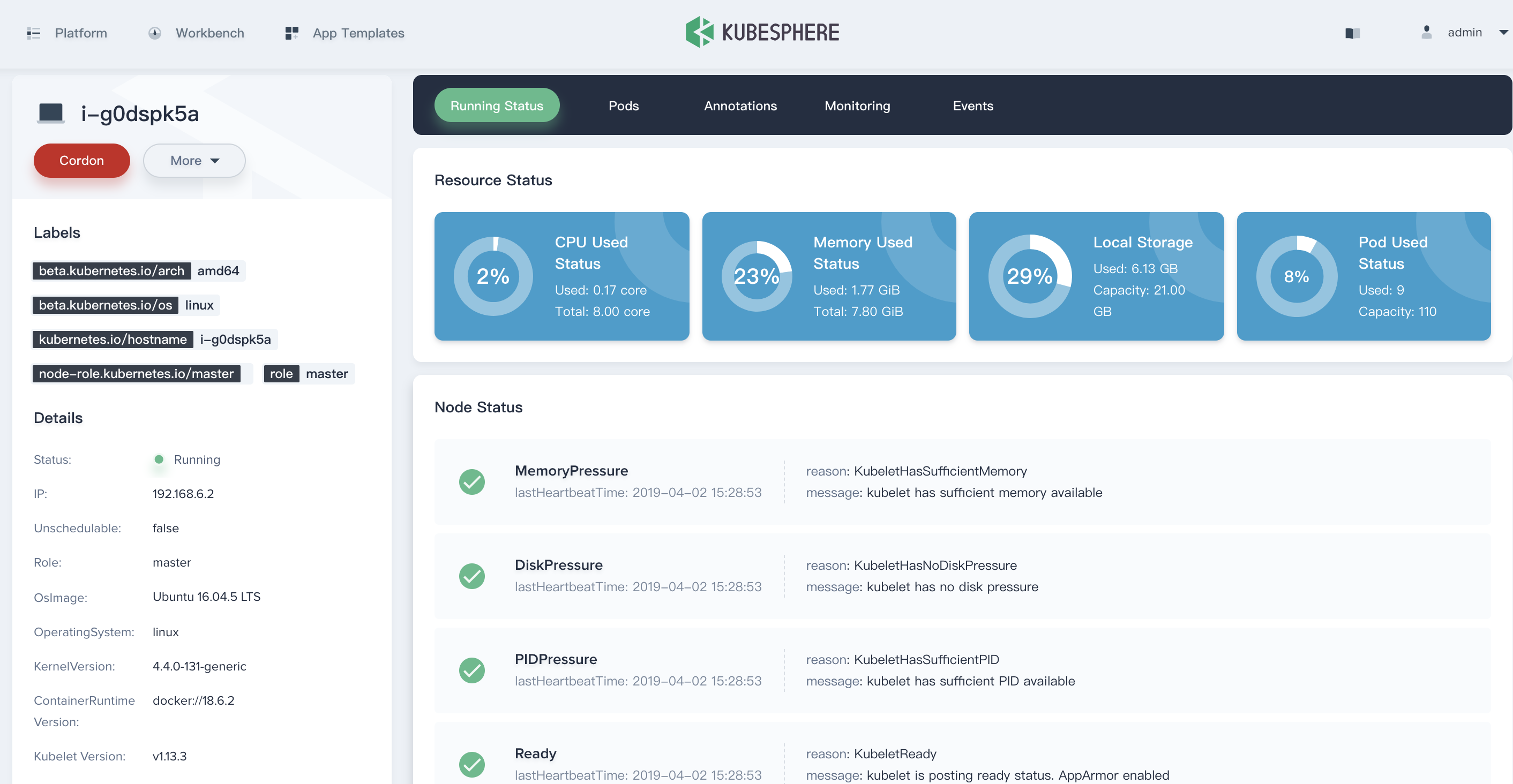
View the Node Details
Click a node in the list to enter its detail page, then you will see the resource and node status, Pods status, annotations, monitoring and events of this node.
Node Status
KubeSphere provides the following five states, the cluster administrator can determine the load and capacity of the current node through the following states, and manage the host resources more reasonably.
- OutOfDisk:If there is insufficient free space on the node for adding new pods.
- MemoryPressure:If pressure exists on the node memory – that is, if the node memory is low.
- DiskPressure: If pressure exists on the disk size – that is, if the disk capacity is low.
- PIDPressure:If pressure exists on the processes – that is, if there are too many processes on the node.
- Ready:If the node is healthy and ready to accept pods.
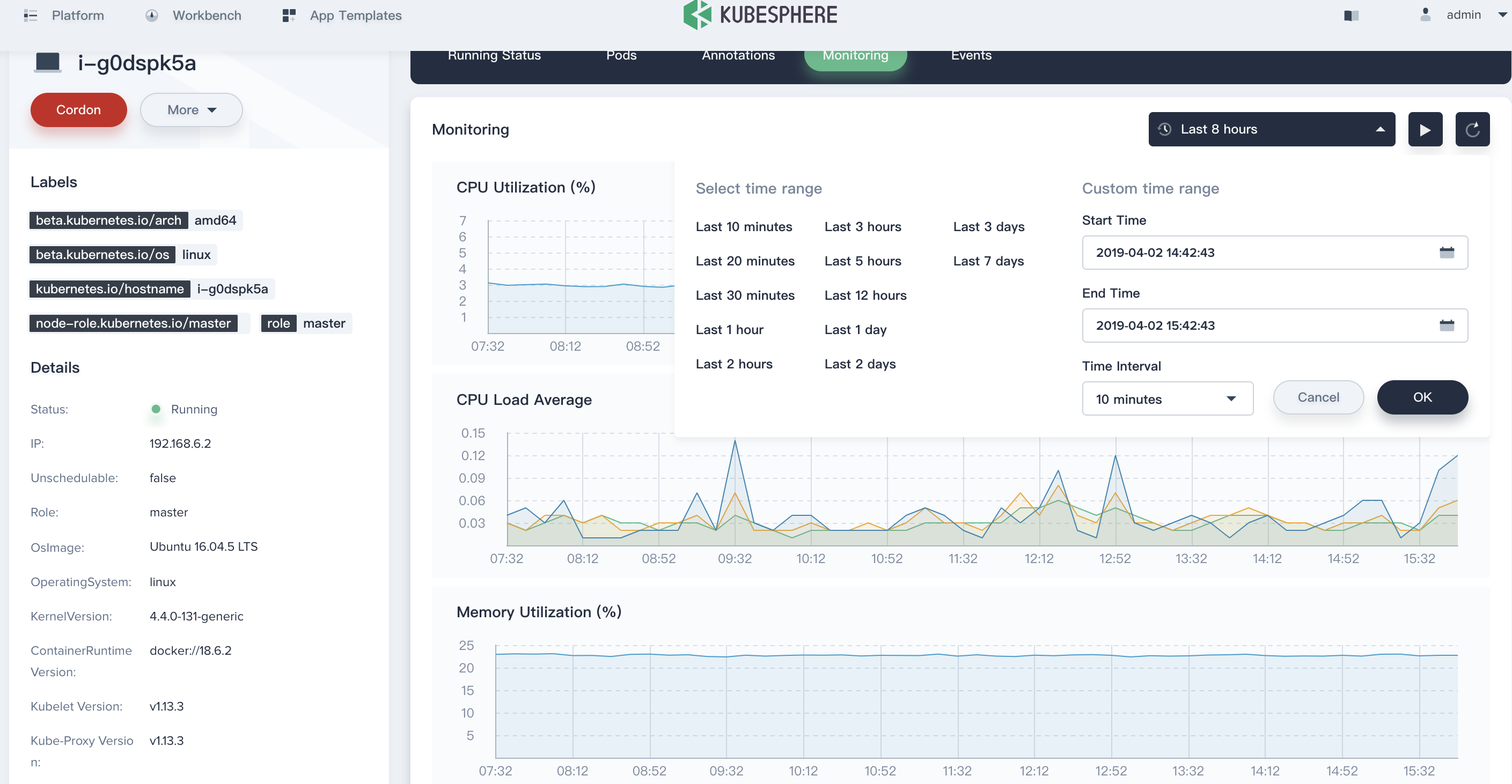
View the Monitoring Graph
It is worth mentioning that node management supports fine-grained resource monitoring, which can filter monitoring data within a specified period to view changes, also supports dynamically watching the monitoring metrics.
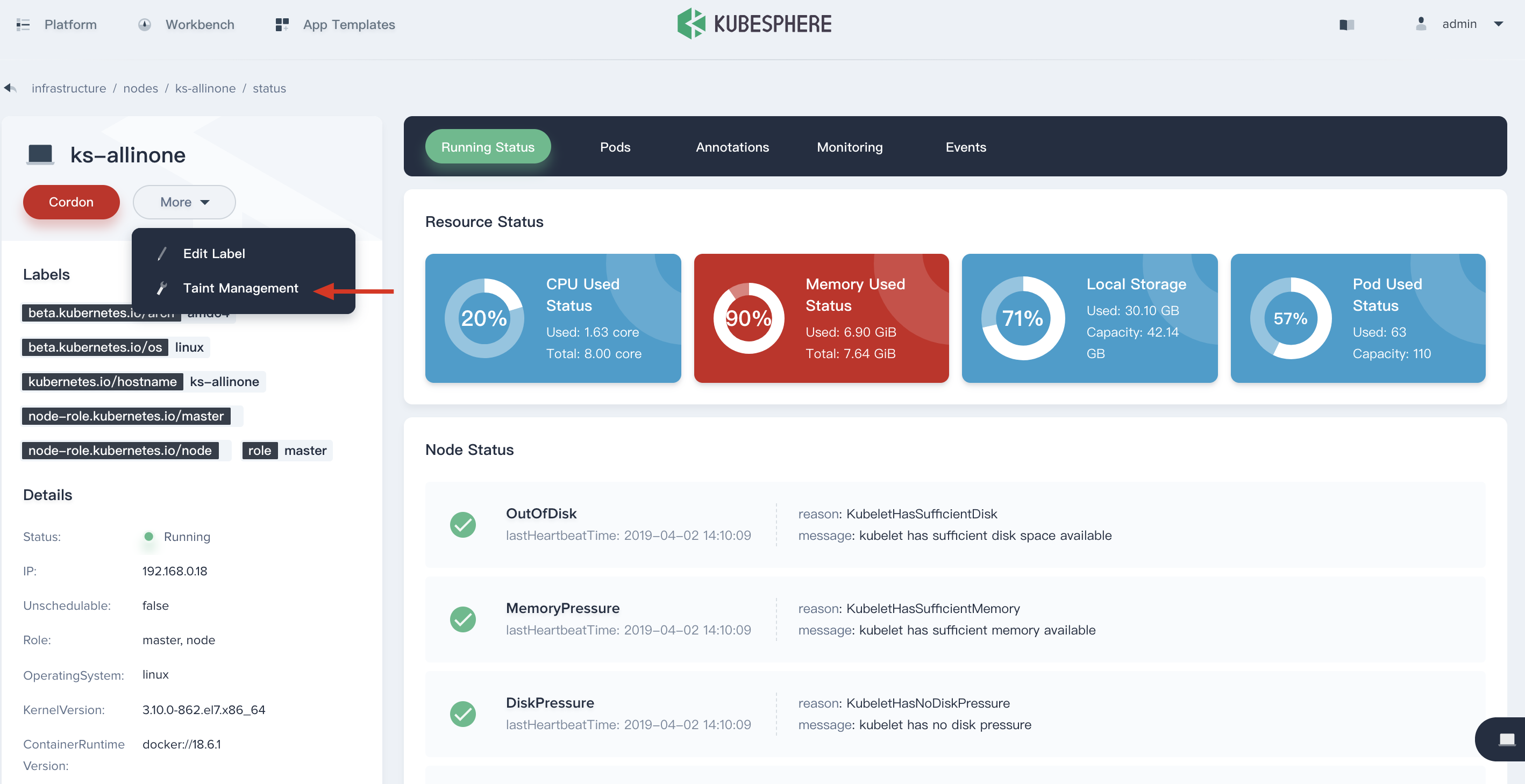
Taints Management
Node affinity is a property of pods that attracts them to a set of nodes. Taints are the opposite – they allow a node to repel a set of pods. Taints and tolerations work together to ensure that pods are not scheduled onto inappropriate nodes. One or more taints are applied to a node; this marks that the node should not accept any pods that do not tolerate the taints.
For example, the memory usage shows up at 90% in this node as following, which means there is not recommended to schedule new pods on this node, you can set a stain on it.
-
Click Taint Management, enter into the taint management pop-up window.
-
Add a row of taint as
key1:value1 NoSchedule, then no pod will be able to schedule onto this node unless it has a matching toleration as following.
tolerations:
key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"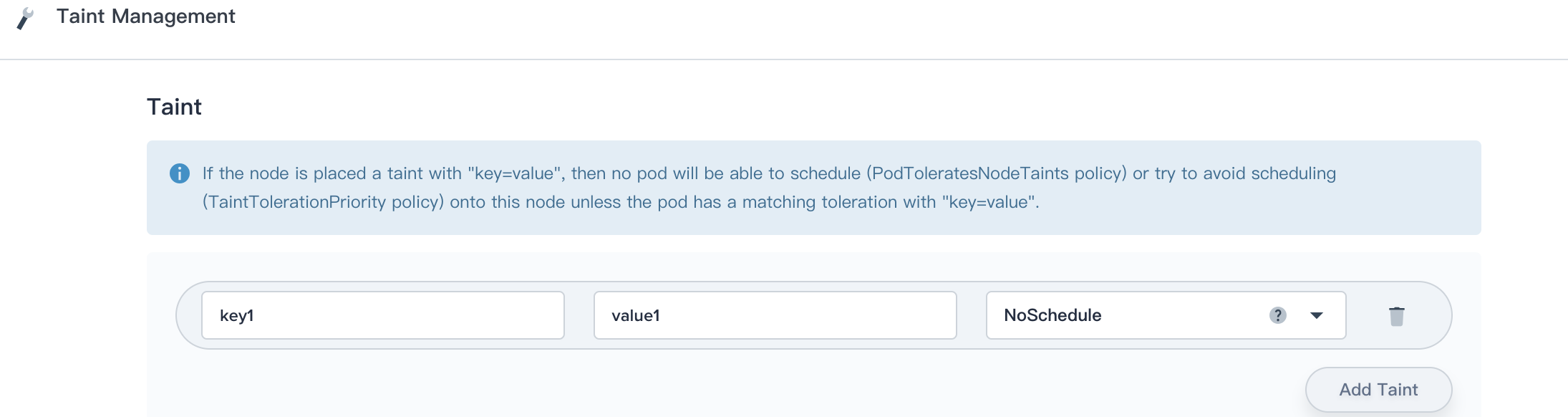
Generally, creates a taint that marks the node as unschedulable by any pods that do not have a toleration for taint with key key, value value, and effect NoSchedule. (The other taint effects are PreferNoSchedule, which is the preferred version of NoSchedule, and NoExecute, which means any pods that are running on the node when the taint is applied will be evicted unless they tolerate the taint.)
There are 3 kind of effect:
- NoSchedule: No pod will be able to schedule onto the node unless it has a matching toleration. It will be able to continue running if the Pod is already running on the node when the taint is added.
- PreferNoSchedule: This is a “preference” or “soft” version of NoSchedule – the system will try to avoid placing a pod that does not tolerate the taint on the node, but it is not required.
- NoExecute: The pod will be evicted from the node (if it is already running on the node), and will not be scheduled onto the node (if it is not yet running on the node). Only the pods that do tolerate the taint will never be evicted.
For example, imagine you taint a node like following scenario:
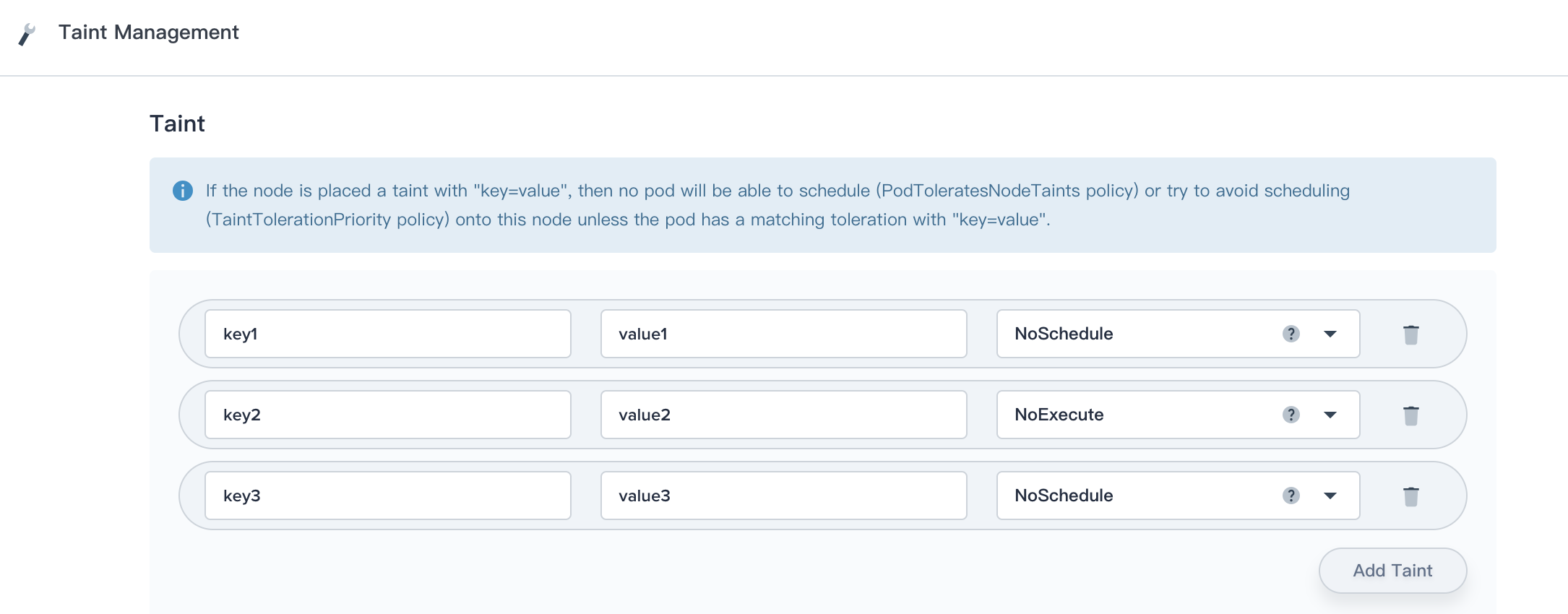
And a pod has two tolerations:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key2"
operator: "Equal"
value: "value2"
effect: "NoExecute"In this case, the pod will not be able to schedule onto the node, because there is no toleration matching the third taint. But it will be able to continue running if it is already running on the node when the taint is added, because the third taint is the only one of the three that is not tolerated by the pod.
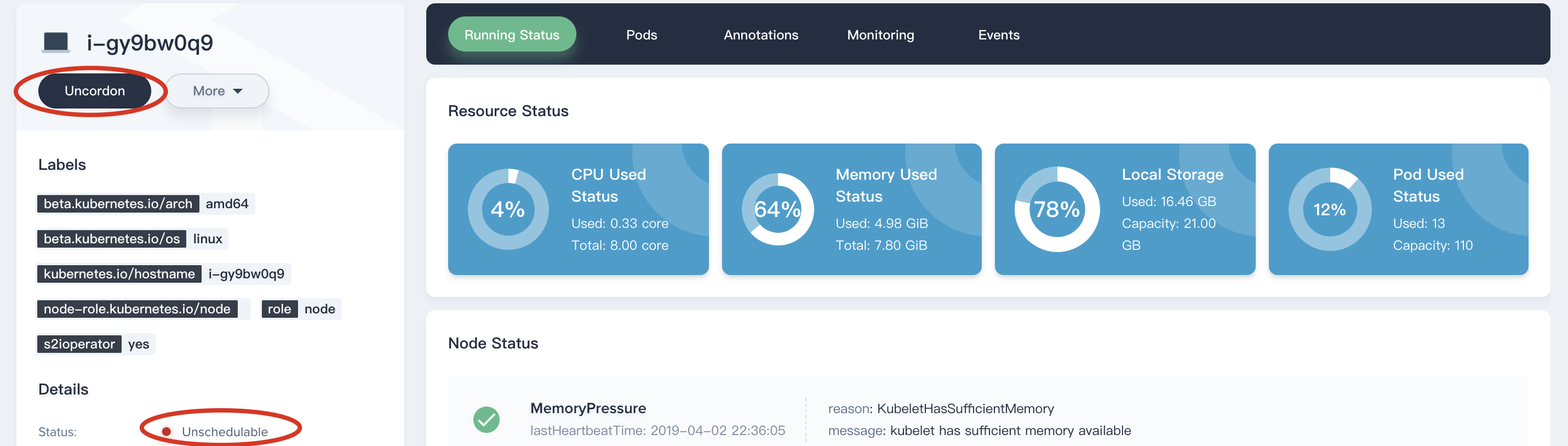
Cordon or Uncordon
Click on Cordon button to mark a node as unschedulable prevents new pods from being scheduled to that node, but does not affect any existing pods on the node. This is useful as a preparatory step before a node reboot, etc.
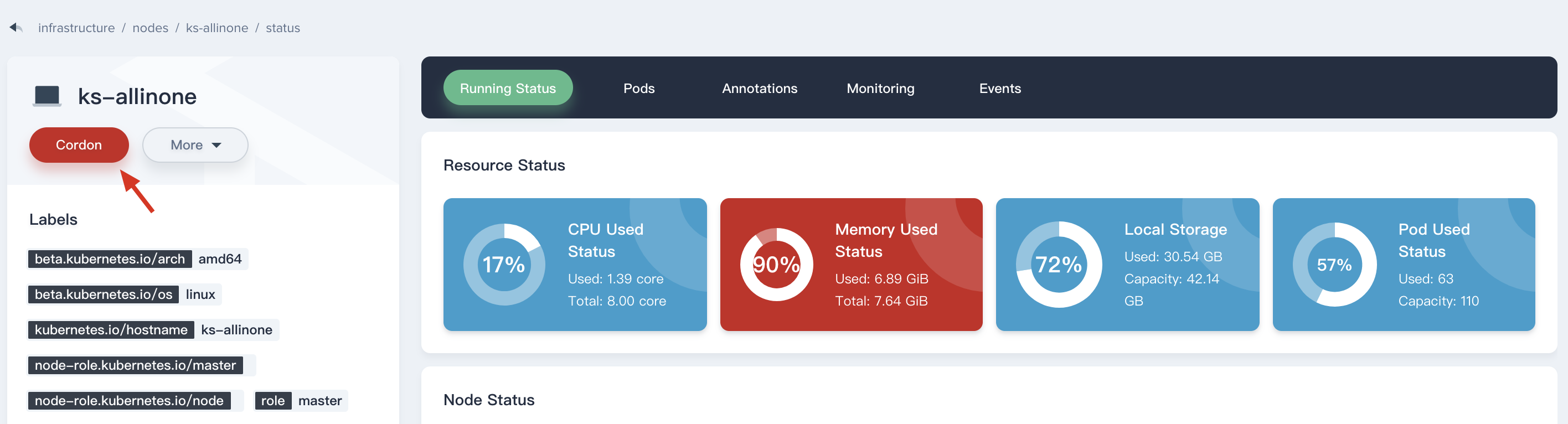
Then you will see the status of this node has changed to Unschedulable. If you need to Uncordon as well.
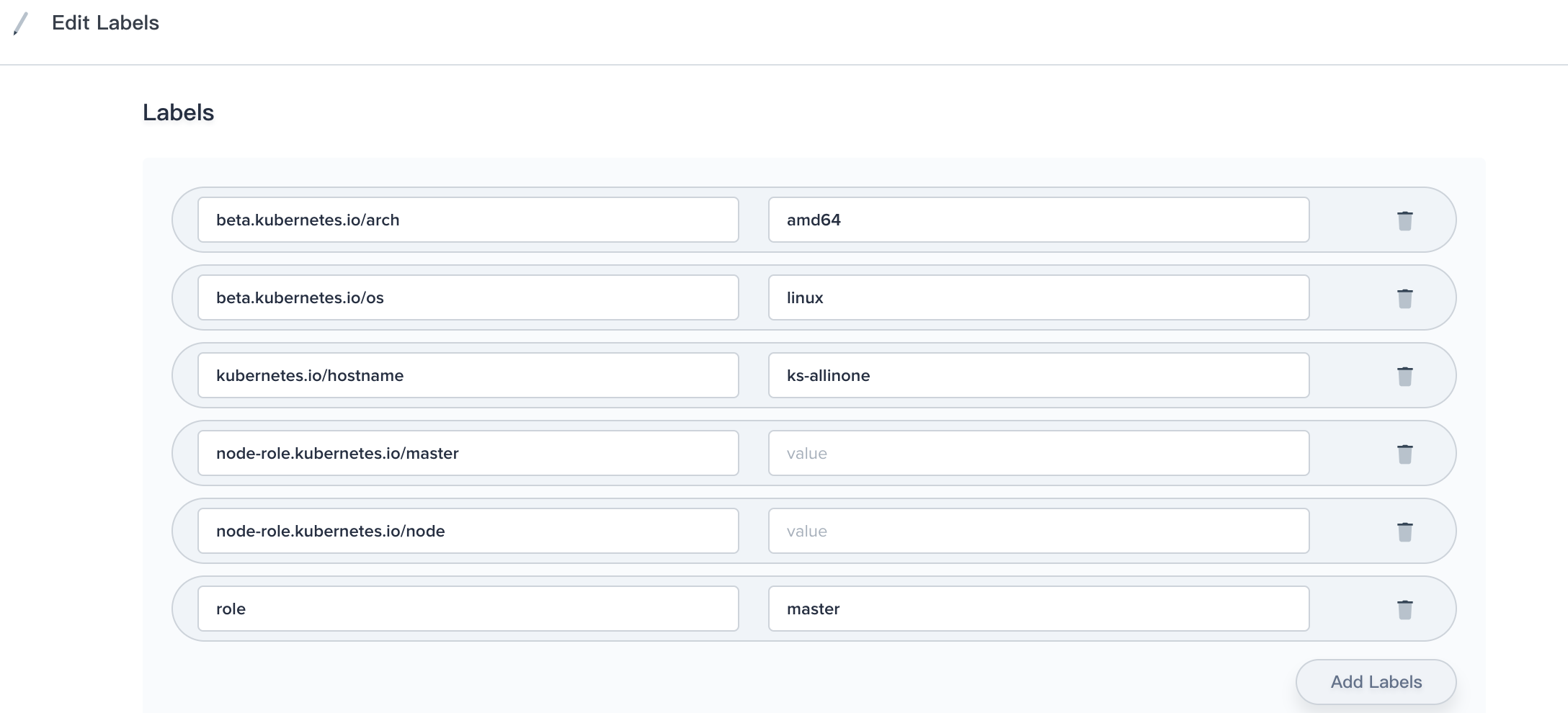
Edit Label
Labels on nodes can be used in conjunction with node selectors on pods to control scheduling, e.g. to constrain a pod to only be eligible to run on a subset of the nodes.
For example, if we set label role=ssd_node to node1, and set NodeSelector role : ssd_node to Pod at the same time, then the Pod will only be eligible to run on the node1.
If you need to edit the label of node, you can click More → Edit Label to update its label.
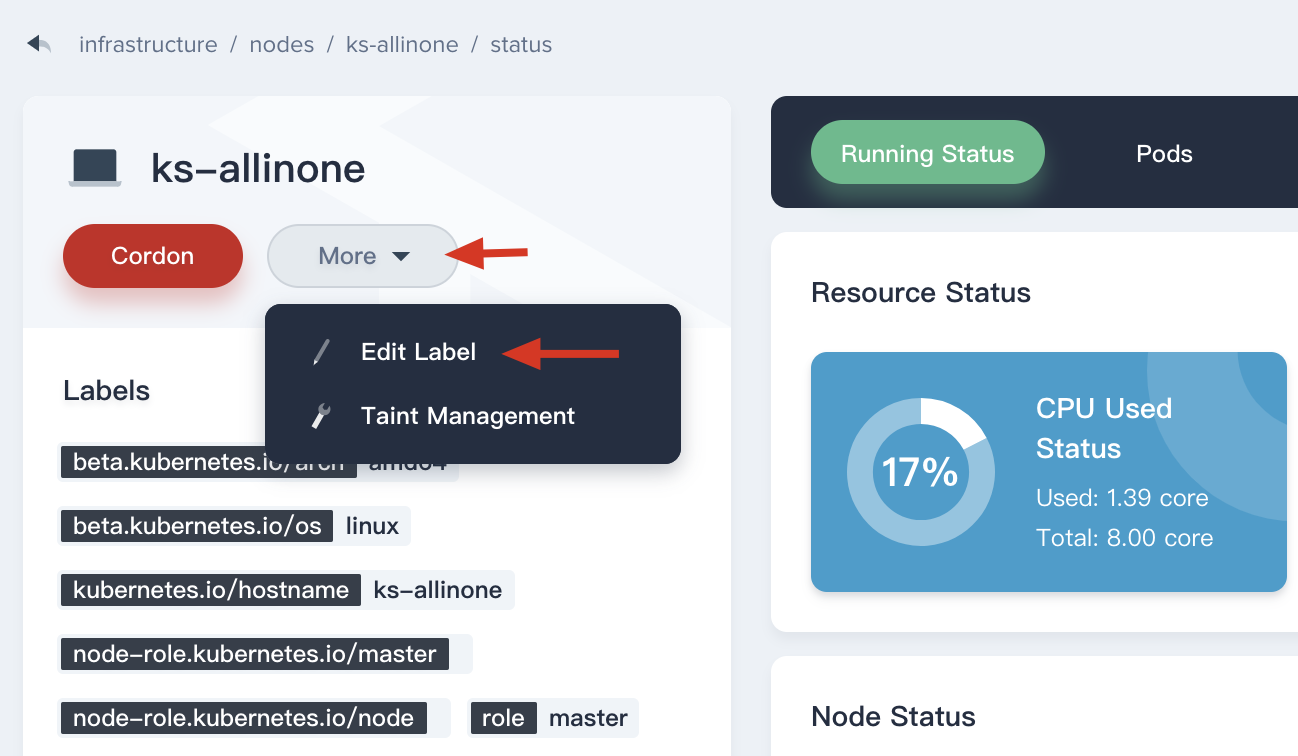
Modify the key-value labels in the pop-up window.